Noticias
DeepSeek lanza modelo con atención dispersa que reduce los costos de API a la mitad
J
Jorge Luis
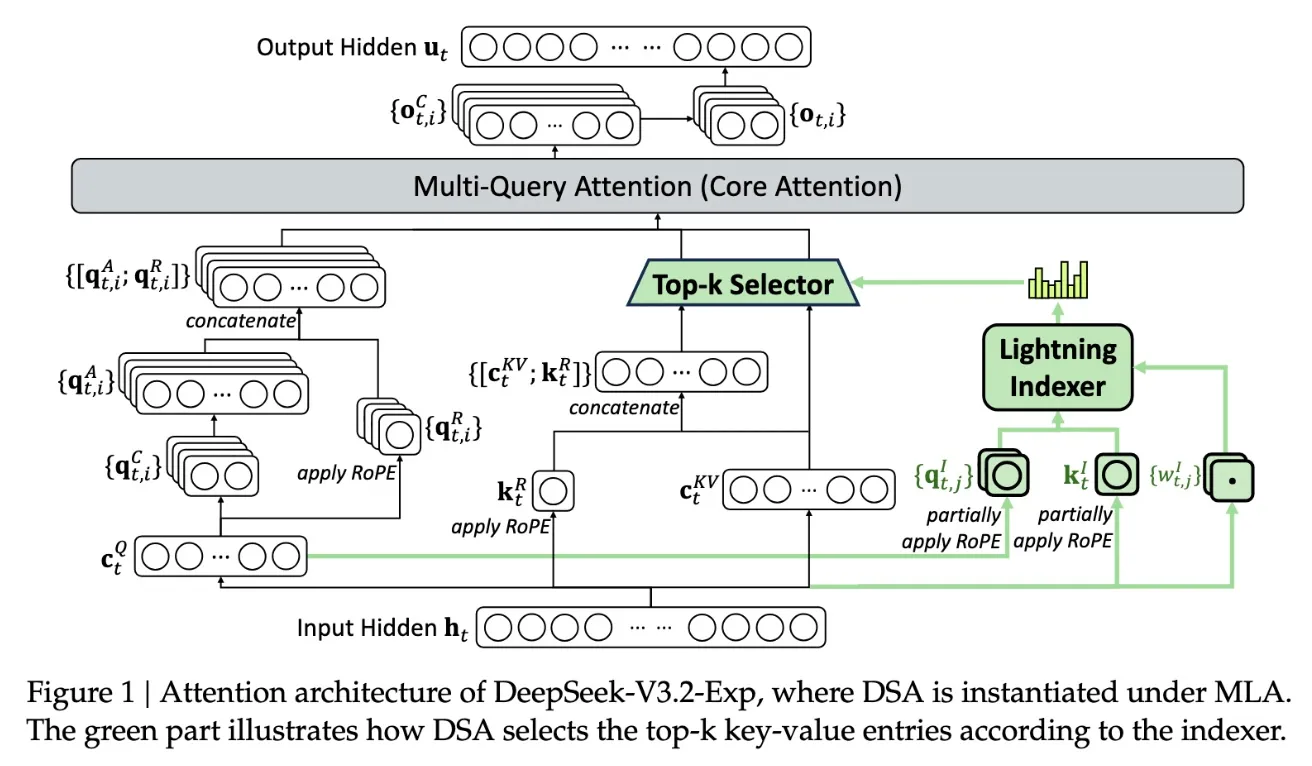
DeepSeek ha presentado su nuevo modelo experimental V3.2-Exp, que incorpora un mecanismo llamado sparse attention (atención dispersa) para hacer más eficientes las llamadas API en contextos de texto largo.
- En pruebas iniciales con contextos largos, este modelo logró reducir el costo por llamada de API hasta un 50 % en comparación con versiones anteriores.
- El modelo es de código abierto y está disponible en Hugging Face, lo que permitirá que la comunidad lo pruebe y valide las mejoras.
- La innovación está dirigida especialmente a reducir los costos de inferencia —es decir, los recursos necesarios para ejecutar un modelo ya entrenado— sin comprometer demasiado la calidad del resultado en tareas con largos contextos (por ejemplo, documentos extensos, hilos de conversación largos).
- La técnica de sparse attention consiste en seleccionar qué partes del contexto “atender” en lugar de procesar cada token con la misma atención, reduciendo la carga computacional.
¿Por qué es relevante?
- Reducción de costos operativos En productos que dependen de llamadas frecuentes a modelos de IA, una mejora como esta puede disminuir significativamente el gasto de infraestructura.
- Escalabilidad inteligente Al optimizar la inferencia para contextos largos, se puede ofrecer funcionalidades más ricas (resúmenes extensos, análisis completos, agentes conversacionales) sin consumir recursos desproporcionados.
- Innovación abierta y colaboración Dado que DeepSeek liberó el modelo en Hugging Face, permite a desarrolladores externos experimentar, mejorar y adaptarlo a casos específicos más rápido.
- Ventaja competitiva para productos AI integrados Si tu herramienta o servicio digital integra IA, incorporar técnicas como sparse attention puede ser un diferenciador frente a productos menos eficientes.
#Cloud#AI#Machine Learning#Productividad